This post was sparked by a tweet from Omar Chaudhuri, regarding changes to Austrian soccer in 2018/19:
Another league going for the split season format, where it’s preferable to finish 7th over 6th. This has to stop. https://t.co/o8dmcPyp24
— Omar Chaudhuri (@OmarChaudhuri) December 2, 2016
I thought I should test this assertion, and found it is true for a range of common scenarios, although the trade-offs are considerable. The results of 40 million league simulations are below.
Background: What do professional leagues want?
We are seeing a growing trend of sporting bodies adjusting their schedules to maximise broadcasting revenue. From the NRL leaving its fixture floating so Channel 9 can put the best teams in the prime timeslots, to MLB introducing wildcard playoffs, to cricket ensuring India and Pakistan are always in the same group, there is a substantial buck to be made by tweaking fixtures. Marketing managers are paid extremely well to dream up ideas that spread games across more eyes and grow the sale price for rights.
In many cases, this aligns with the fan who sees more televised sport and the excitement of his/her team being in contention for longer. But deviating from the pure formats of round-robin* or straight knockout brings the risk of what economists call perverse incentives.
We have already had many situations where both teams would be happy to settle for a draw to qualify for the next stage of a tournament at the expense of a third. Even worse is when either team would achieve a better outcome by losing a particular match. This year, Graham Kendell and Liam Lenten published a paper with a collection of farcical cases called When Sports Rules Go Awry in the European Journal of Operational Research. As new formats are brought into national leagues, experts must test them as thoroughly as Durex for any holes that lead to unwanted outcomes. 
Let’s be clear: despite exhortations to play your best, if the tournament structure favours a loss it is rational to aim for it. It just feels and looks terrible, so people get disqualified for it after the fact. It behoves sporting bodies to carefully design their tournament formats with this in mind. How do you blame the competitors when it is the governance that failed?
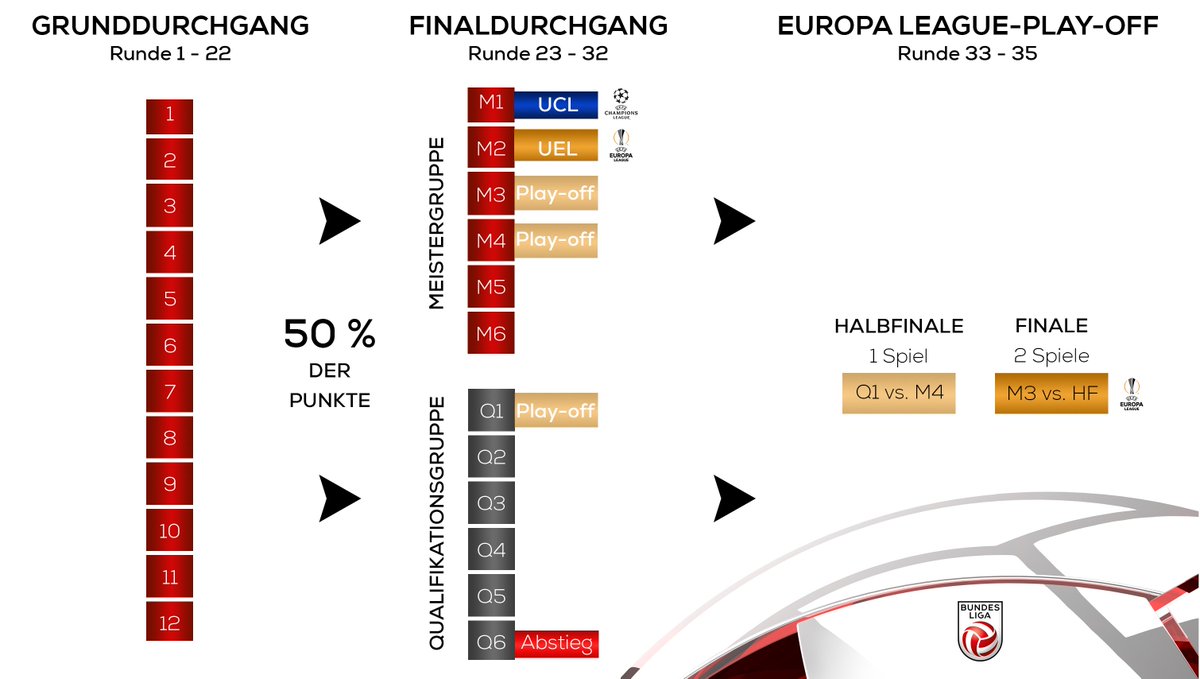
The new Österreich Fußball-Bundesliga format
In 2018/19, the top tier of the ÖFBL (Austrian Football League) grows from ten to twelve teams, and in an effort to increase interest for mid-ranked teams the governing body has decided to split them after a double round-robin (Rounds 1-22). Points from those 22 matches will be halved. The top six will then play amongst each other twice, while the bottom six do the same (Rounds 23-32). The twist is that those bottom six remain in contention for a Europa League playoff berth, and all the money that could bring. Even better for the ÖFBL, this creates three end-of-season playoff matches that should attract eyeballs and euros.
The first problem is that Austria is a moderately weak league (ranked 16th in Europe), recently dominated by Red Bull Salzburg (seven of the past ten titles) and the two large Vienna clubs (Austria Wien & Rapid Wien). On current allocations, the league receives just one Champions League ticket, and two† for the lesser Europa League (nominally one into the Second Qualifying Round, and one into the First Qualifying Round).
Under the new system, the team that finishes “seventh” — i.e. best of the lower half (Q1) — will host the team that finishes fourth (M4) in a single playoff. The winner of that will play home & away against the third-placed team (M3) for the last Euro spot.
The ÖFBL did receive outside help to construct and test its new system from Hypercube, based in the Netherlands, who have also consulted to other national leagues.
Benefits
- Teams in the bottom half are playing for something until later in the season
- More matches between two good teams
- More projected revenue from attendance and rights (I assume)
- As a whole, there is still a sensible payoff structure with respect to the strength of each team, compared to round-robin
- Halving the points means that later games matter more, freshening the incentive
- The single playoff hosted by the best of the bottom half will often be a 50/50 game, as the home ground advantage cancels out the skill advantage of the fourth-placed team
This is not repechage
Repechage is a very appealing concept from a tournament design point of view. If you have an initial short classification stage, sometimes good competitors will fail to win through just by luck. Giving them a (tough) route to remain in contention for the trophy can be an excellent way to maintain interest while keeping the payoffs fair and incentives clear. I’ll revisit my 2010 World Cup proposal some time soon, as an example.
I would not call the ÖFBL proposal repechage. The teams have a full double round-robin, which will usually provide enough resolution to the order. The number of cases where team 7 is actually better than team 5 (or 4) starts to diminish. Why give them a leg up?
On the flipside, team 7 is now excluded from winning the title or indeed finishing in the top three. A top team that somehow found itself 7th after two round-robins would have made the top three 40% of the time after the addition of a third full round-robin.
Methodology
To simulate the plan, I had to generate plausible team strengths and compare the ÖFBL schedule with the alternative. The current ten-team league has a quadruple round-robin of 36 matches, impossible with 12 teams. So I went for a triple round-robin over 33 rounds as the comparison, alternating the extra home game from simulation to simulation. I did not halve the first-stage points in this scenario.
Team strengths were drawn from a Skew Normal Distribution, which can mimic a situation where you have the upper tail of a natural (Normal) distribution with a mask (Normal CDF) indicating that lesser teams have been relegated or otherwise sit in a lower division. I used the observed average home (1.58) and away (1.30) goals to fit the distribution, and checked that the simulated results (via Poisson random variates, Mersenne Twister algorithm) passed the sniff test for how often the top teams won.
Each set of random team strengths was used for 1000 simulated leagues, then a new bunch was drawn. In each set, the team with the highest strength was labelled A, the next highest B, all the way down to the weakest team L. 20,000 different sets were used for each type of fixture, meaning 20,000,000 full simulations of each type.
What went wrong?
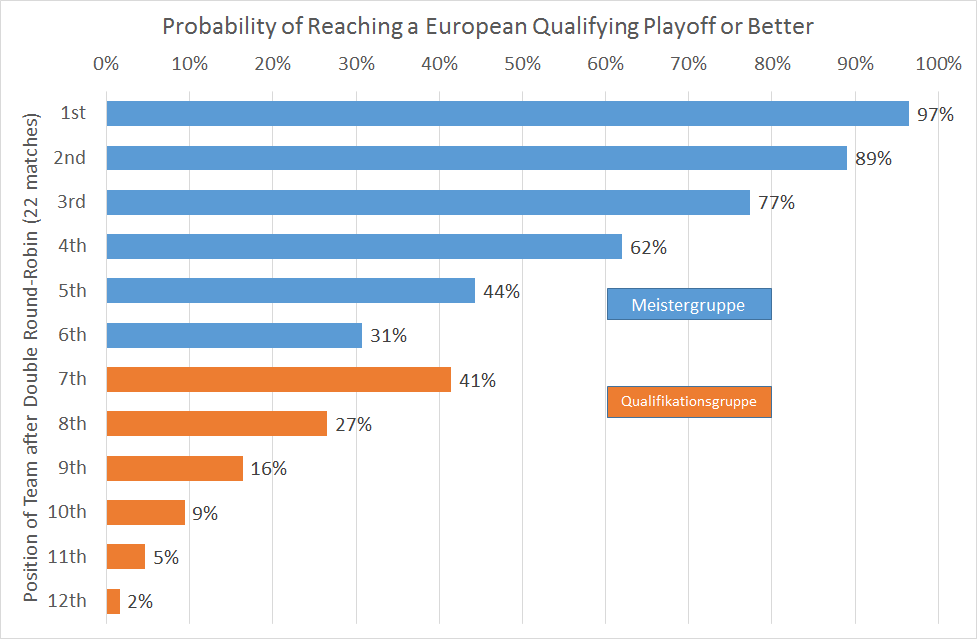
This is the plainest way to see the thing that makes people uneasy: team 7 has a higher chance of reaching a playoff than team 6. In fact, it’s nearly as high as the chances of team 5. Post-season (as the Americans like to call it) is a clear marker of success, and the team that misses the elite group cut is better placed to achieve it.
But let’s consider the value of these playoff positions in terms of the likelihood of reaching the money rounds in Europe. Q1 will play M4, the winner of that playing M3 for the Europa League position. That position will be the lowest ranked of the Austrian Europa teams, and play in the 1st or 2nd Qualifying Round, needing a few wins over European rivals of similar strength to make the richer group stages. Meanwhile, M2 is in the 2nd Qualifying Round at least. Of course, the champion M1 has a Champions League chance, worth even more.
Let’s make simple metric that says a Champions League berth is worth 8 points, double that of the Europa League: 4 points. Reaching the ÖFBL two-legged playoff is then worth 2 points, and the Q1 vs M4 match-up is worth 1 point to each competitor. The next graph shows the average value for a team in each position after Round 22.
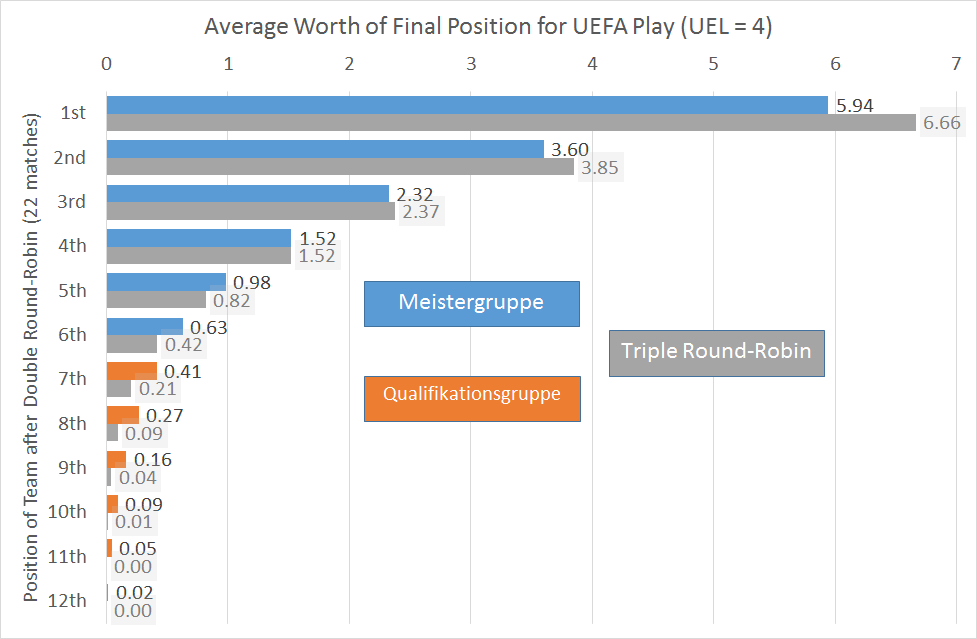
The design looks to have achieved what it set out to do: a smooth decrease in the value of the position after Round 22. The team that has dominated the first two-thirds of the season is going to have to work harder as its earned points are halved, and there is more chance of the bottom eight moving into contention as planned.
Looking at teams labelled A because their intrinsic strength was the highest of the 12 teams, they win the trophy 59% of the time under the ÖFBL model and 60% under 3RR. In fact after 20,000,000 league simulations of each type, the profile of each labelled team finishing in each position is so similar as to make no difference. The Meistergruppe double round-robin does a decent job of bringing the cream to the top. There are quirks: for instance, the sixth-strongest team F‘s most likely final position is not M6 (14.6%), but the positions on either side: M5 (14.7%) or Q1 (14.7%). Nothing too serious.
Now, like the Durex factory workers, we’re going to do some stress-testing. Does this new model work well for every team and scenario, or just on average?
| 6th after Round 22 | 7th after Round 22 | |||
|---|---|---|---|---|
| Playoff or better | Avg Metric | Playoff or better | Avg Metric | |
| Σ | 31% | 0.63 | 41% | 0.41 |
| A | 74% | 2.60 | 75% | 0.75 |
| B | 65% | 1.73 | 69% | 0.69 |
| C | 55% | 1.21 | 64% | 0.64 |
| D | 44% | 0.87 | 59% | 0.59 |
| E | 34% | 0.64 | 54% | 0.54 |
| F | 27% | 0.486 | 49% | 0.490 |
| G | 22% | 0.39 | 43% | 0.43 |
| H | 19% | 0.32 | 34% | 0.34 |
| I | 16% | 0.26 | 27% | 0.27 |
| J | 13% | 0.21 | 21% | 0.21 |
| K | 10% | 0.16 | 16% | 0.16 |
| L | 8% | 0.11 | 11% | 0.11 |
As we established earlier, the average 6th-placed team has less chance (31%) of making the Austrian playoffs than the average 7th-placed team (41%), but the net value of their playoff position will be greater (0.63 vs 0.41). For strong teams, there are clear benefits in finishing in the top half and competing for the top three. The trouble comes with teams F, G, H, & I: in each case, not only is the chance of a playoff nearly doubled by dropping into the bottom half, but the simple metric we calculated shows they have a slight benefit in doing so.
In other words, for the teams that are most likely to be on the cusp of qualification, it is better to play ten matches against weak opponents and hope for Q1 than play ten matches against strong opponents attempting to land in M4 or higher. If the team is a long way behind the top four on points, it has extra incentive to tank. The only clear reason for aiming for 6 over 7 would be if a strong team or two has accidentally underperformed into the bottom half.
We predict teams with sufficient mathematical nous will be confronted with this scenario some time in the next few seasons, and the ÖFBL’s governance will come under heavy fire. Nice try, it just needs a tweak before that happens.
† There are three Europa League slots, but one is given to the Austrian Cup winner. Also, if Austria climbs to 15th in the UEFA coefficient, it will gain a second Champions League berth. This makes qualification from fifth (M5) possible, which would imply 6 is preferable to 7 in all cases.